Spoiler: yes, it is worth the hype.
We’re convinced that recent regulatory advancements (data interoperability, pricing transparency, digital prior authorization) and technical unlocks (foundation models for natural language processing, speech understanding, and OCR) remove key rate-limiting factors and pave the way for revenue cycle management (RCM) centered around software, not people.
But, before we go crazy applying LLMs to healthcare, we need to go back to the basics and understand the medical billing status quo.
Medical Billing Today: A Tale of Four Trillion Dollars, Two Hundred Thousand+ Medical Billers, and Unstructured, Unreadable Data
Every year, the Center for Medicare and Medicaid Services (CMS) publishes some really cheery statistics on US medical expenditures. 2021 saw roughly $4.26 trillion flow through the healthcare system, split across $3.02 trillion in insurance payments, $433 billion in patient responsibility, and the rest from elsewhere.
For the amount of money flowing through the healthcare system, there’s a staggering lack of software. Payment flows are stitched together by faxes, voicemails, and maybe a few APIs, plus the hundreds of thousands of people employed by health systems outsourced RCM providers to usher the process along.
Which is unintuitive: you’d think computers are more effective than people because medical billing is so repetitive and rules-based. That’s partially true – it is repetitive and rules-based – but nonetheless employing armies of people has historically been the most effective way to handle medical billing.
Let’s dig into why.
The problem starts with the steps required to bill a given encounter. If a single patient encounter requires a patient referral, insurance verification, prior authorization from the payer, coding up the visit, and some negotiations between the payer and provider, a sample of the data generated during the process looks something like:
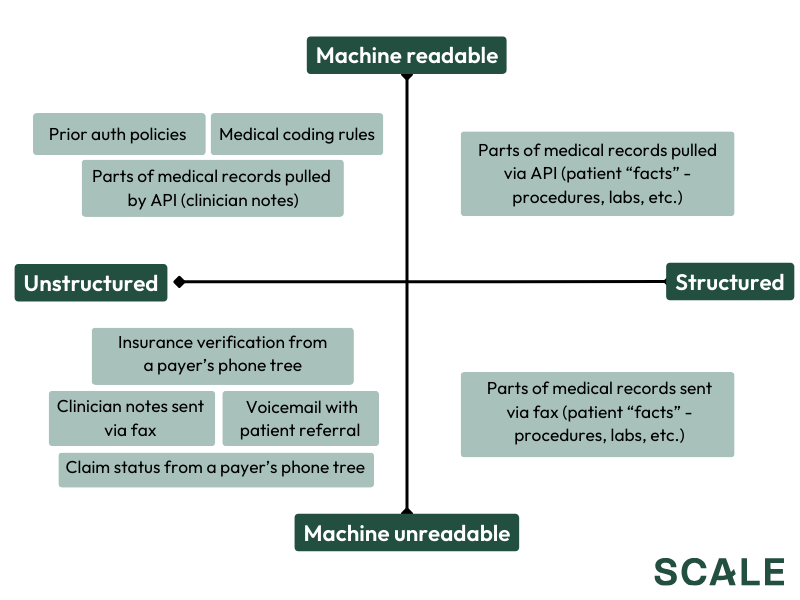
There’s obviously more to it, but the point stands that billing workflows involve a ton of unstructured and/or unreadable information, and software can’t eat a workflow if it can’t work with its underlying data.
Of course, the fact that some data is machine readable (albeit often unstructured) suggests that software can probably automate some workflows. That’s true to an extent, but you quickly run into two limitations:
- A lot of the subtleties involved in billing aren’t really observable from written policies alone: computers can’t intuit idiosyncratic payer behavior from a series of written rules, so even if you can translate a coding policy into a rules engine you lose a ton of nuance.
- Electronic health records (EHRs) vary wildly by health system, so even just accessing medical records – let alone propagating changes back into the EHR – can be painful for a computer to do autonomously (vs. a human manually logging into Epic/Cerner/eCW/<pick your obscure, specialty-specific EHR> to pull data and enter in information).
So yes, software can perform some basic tasks, but the perfect storm of unstructured + unreadable data, payer idiosyncrasies, and EHR variance forced anyone running an RCM business to confront two brutal realities:
- Executing most billing workflows required meaningful humans in the loop, both to clear up log jams and leverage institutional knowledge.
- Deploying software required serious implementation work to integrate into systems and build out bespoke rules engines and deep-learning algorithms.
This then meant that, in most cases, it actually was most efficient to barely have any software and just throw bodies at the problem (hence why R1, one of the largest outsourced RCM vendors, employs ~30,000 people and operates at a ~20% gross margin).
Regulatory Advancements + Technical Unlocks = Usable Data
Software can’t automate revenue cycle processes until it can work with the underlying information. That’s where regulatory advancements and technical unlocks come in.
Regulatory Advancements: Fixing Incentives and Unlocking Data
The harsh reality is that EHRs and Payers have outsized impact on revenue cycle processes, yet are rarely incentivized to (a) bring offline processes online and (b) break down data barriers. Removing a ton of nuance, it often comes down to two reasons: either it’s actually far more efficient to use humans vs. computers (for all the reasons outlined above!), or, more insidiously, there’s a competitive advantage in maintaining data silos and arcane processes (e.g., it’s in Epic’s advantage to keep customer health records inside its own ecosystem). Both lead to very little advancement without some sort of intervention.
The government recognizes these pitfalls and, in response, is introducing policy that encourages interoperability and transparency across the industry. There are three policies in particular we’re excited about:
- The 21st Century Cures Act promotes interoperability across electronic records and ensures that all individuals and their families and providers can access their medical history.
- Pricing transparency rules mandate that payers and providers publish their reimbursement rates.
- A recent proposal from CMS, if implemented, would digitize prior authorization processes and require payers to offer more transparency when denying care.
All three of these take offline processes online and mandate data accessibility – which matters because every piece of data that’s turned machine-readable and every new data source removes a rate-limiting factor in RCM automation.
Of course, regulatory change isn’t enough. Interoperability rules have been around since 2015 and pricing transparency has been in the works for years, yet health data is still really hard to work with and payer policies remain mysterious. The speed of progress ultimately comes down to legislative enforcement, incumbents adopting new technologies, and entrepreneurs innovating in the face of it all.
AI: Helping Data Escape Unstructured, Unreadable Purgatory and Enter Structured, Readable Paradise
Regulatory changes and process digitization don’t change two realities: a lot of data is stuck inside dense, technical written language (e,g, patient histories inside medical records, payer policies, etc.), or, worse, wholly unreadable formats (e.g., insurance verification on payer phone trees, anything sent over fax).
LLMs are the first piece of the puzzle. Language models are really good at two things: structuring data and reasoning given a set of rules, which means they can work with all the rich data stuck inside dense, technical written language: the 50 page prior auth policy that used to require an incredibly complex, hard-coded decision tree instead becomes a prompt input and the LLM can work its magic (oversimplification, we know, but that’s the idea).
When you combine that capability with the aforementioned regulatory tailwinds and a few adjacencies (i.e., use some OCR to read a fax, a voice bot to call a payer, etc.), AI can help a lot of problematic healthcare data escape unstructured, unreadable purgatory and move up into structured, readable paradise.
Usable Data + Intelligent Software = Incredible Opportunity
AI enables machine-driven RCM: now that software can work with the underlying data, you can build intelligent software that’s seen thousands of billing events and has the “institutional knowledge” and process know-how of a team of experienced medical billers.
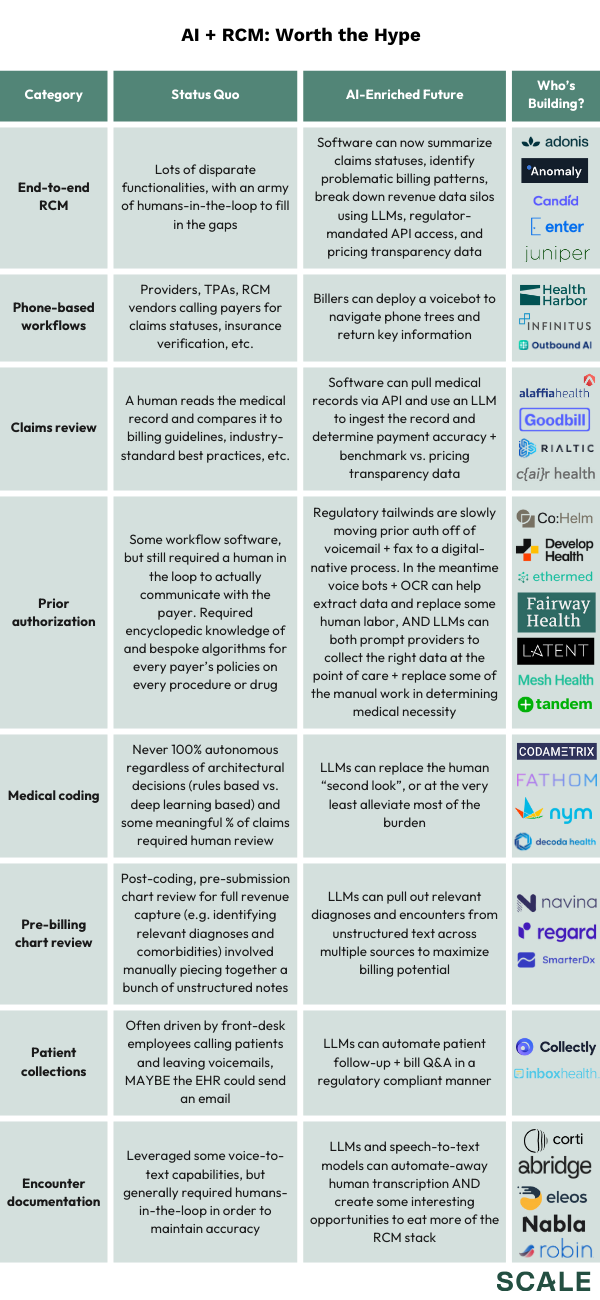
Clever combinations of regulatory and technical unlocks create a ton of opportunity, both for later-stage startups with existing customers and new founders building from scratch. In lieu of trying to be an expert on any single application, below is a (non-comprehensive!) smattering of ideas and companies we’re excited about:
The Open Questions
The above isn’t exhaustive in terms of how AI can impact the RCM process, let alone healthcare more broadly, and there are still so many open questions. To name a few:
- What has platform potential vs. doomed to remain a point solution?
- Will hospital and payer leadership actually trust “fully-automated” solutions, or will there always need to be a nominal human-in-the-loop to gain customer trust?
- Are computers actually more effective than humans – combining pricing transparency data with historical claims acceptance / denial rates certainly helps algorithms understand payer idiosyncrasies, but will that ever be as effective as a true domain expert?
- How will software manage interoperability across solutions and between parties?
This barely scratches the surface – surely, there are more we haven’t thought of yet.
Nevertheless, we’re seeing some of the most compelling tailwinds since the advent of the EHR, and I have full confidence that some incredibly talented entrepreneurs will figure it out. If you’re spending time here, I’d love to chat about everything RCM!